还在因训练神经网络时为调整优化器参数而头疼不已吗?谷歌大脑新推出的VeLO优化器,直接免去了参数调整这一环节,其效果相较于人工设计的还要更好,甚至比经过精细调整的Adam快4倍有余,这样的一波操作,让不少开发者看到了希望喽。
免调参优化器是怎么来的
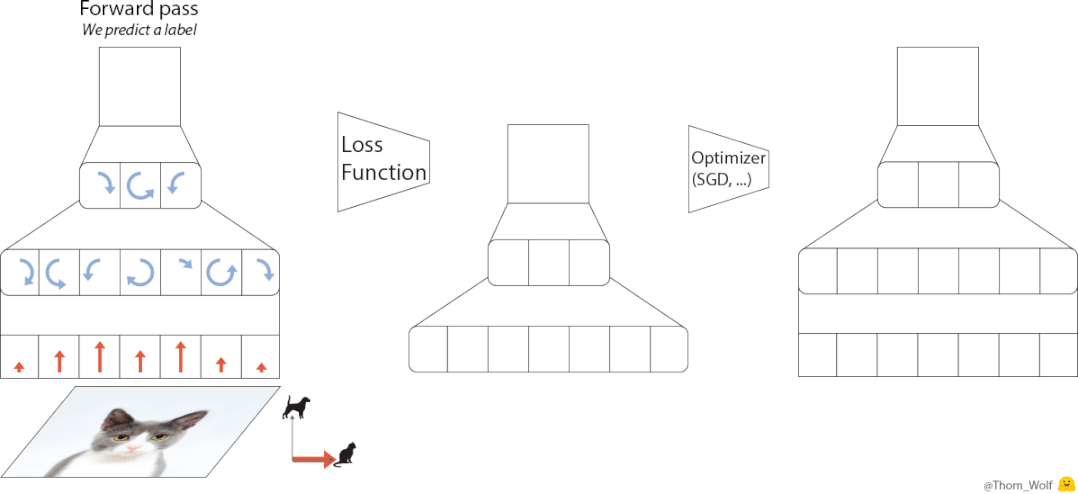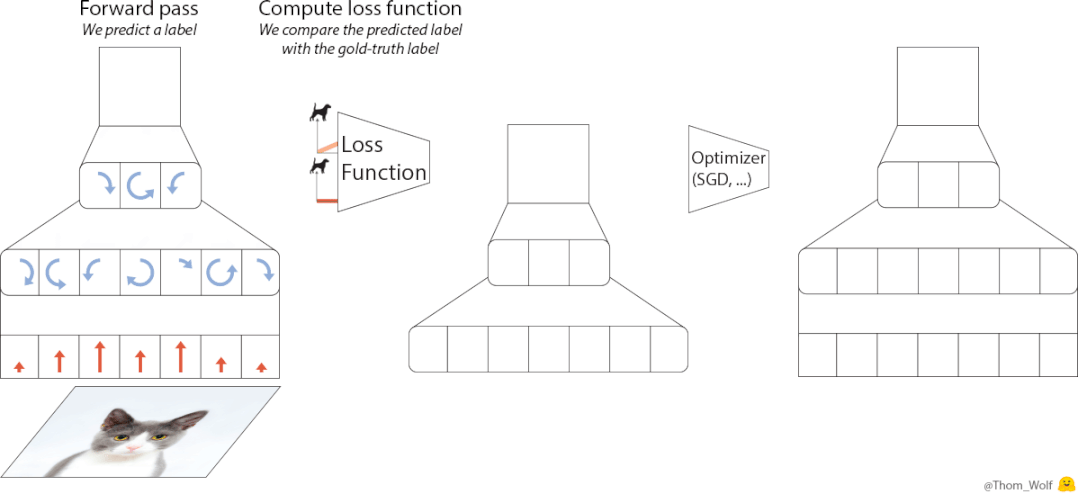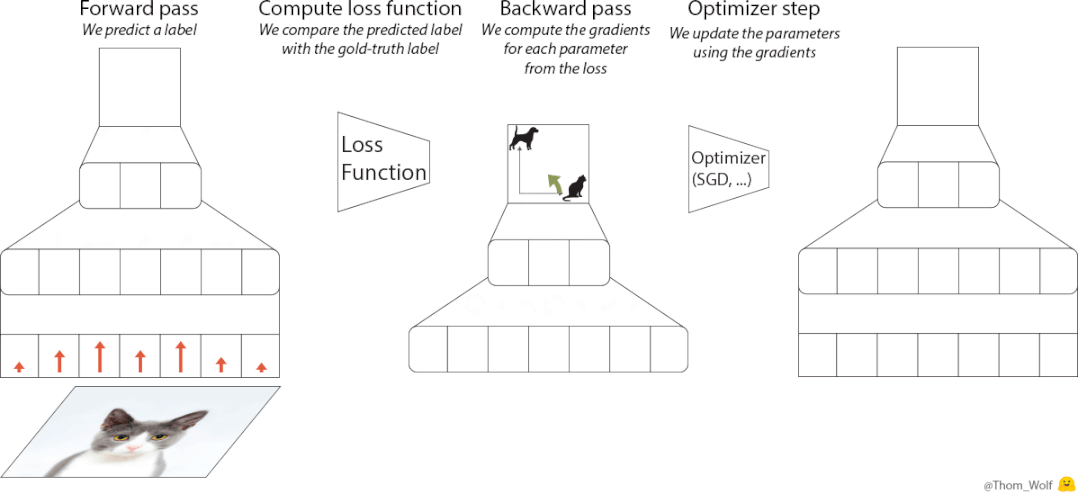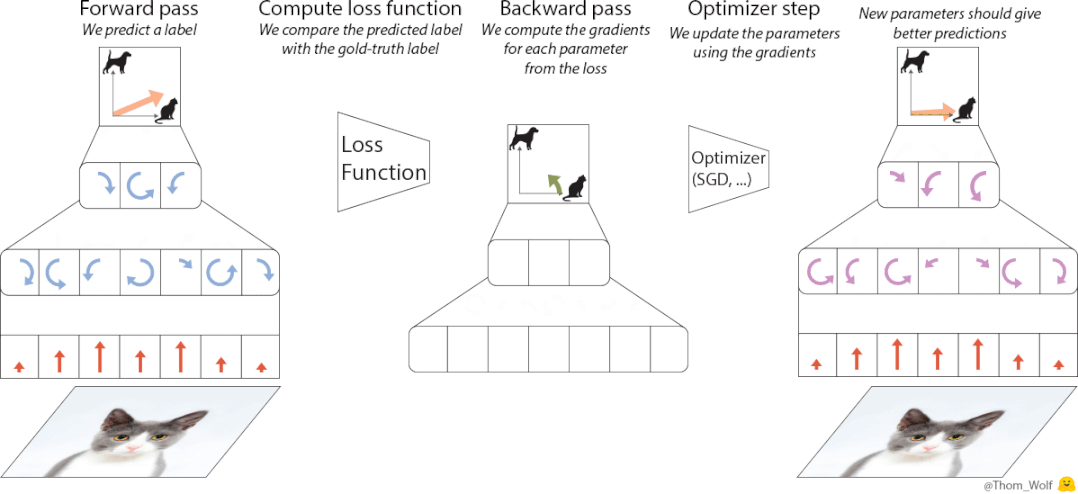
神经网络训练期间,优化器承担更新模型参数之责,其对模型收敛速度以及最终成效有着直接影响。传统优化器像Adam、SGD,均需人工去调整学习率等超参数,此过程既耗时又依赖经验。谷歌大脑的研究人员认为这事颇为矛盾:AI应用已然如此广泛,然而训练AI的工具却依旧需要人工手动去调整。
然后,他们借助AI去搞设计优化器这事儿。此思考方向是基于元学习的,使得优化器从数目众多的训练任务当中去学习怎样更新参数,进而掌握普遍通用的优化知识。历经处于4000个TPU上运行一个月时间长达的大规模训练之后,VeOL最终诞生,它能够自行适应各不相同的任务,压根儿完全不需要人工去进行参数调整。

架构设计背后的巧思
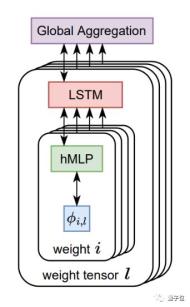
名为VeLO的事物,其内部结构是由LSTM以及超网络MLP组合而成的,每个LSTM起着负责设置多个MLP参数的作用,并且这些LSTM之间借助全局上下文信息相互配合,这样的设计使得VeLO能够依据当前梯度和参数状态,动态地决定怎样更新参数。

开展训练之际,VeLO将参数值以及梯度当作输入内容,输出那些有待更新的参数。它仿若一位见识过不计其数优化实例的行家老手,只要瞧见梯度,便晓得该以怎样恰当的方式去进行调整。借助这种基于元训练的途径,VeLO具备了极为丰富的优化经验,从而能够去应对林林总总的不同类型任务。
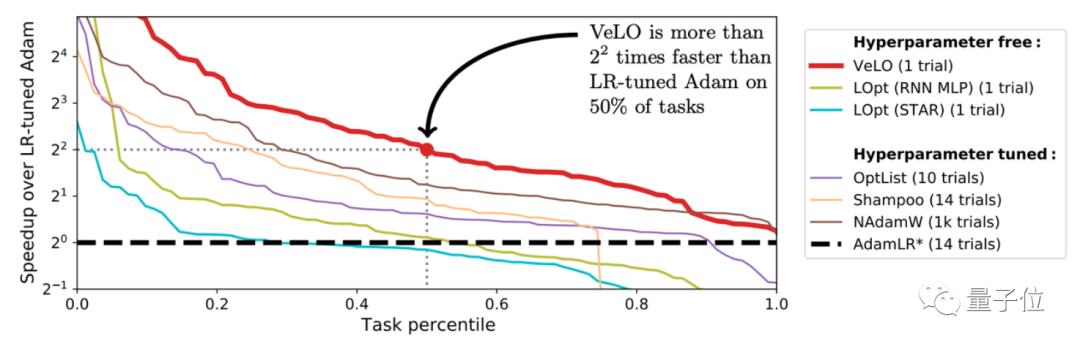
效果对比让人眼前一亮
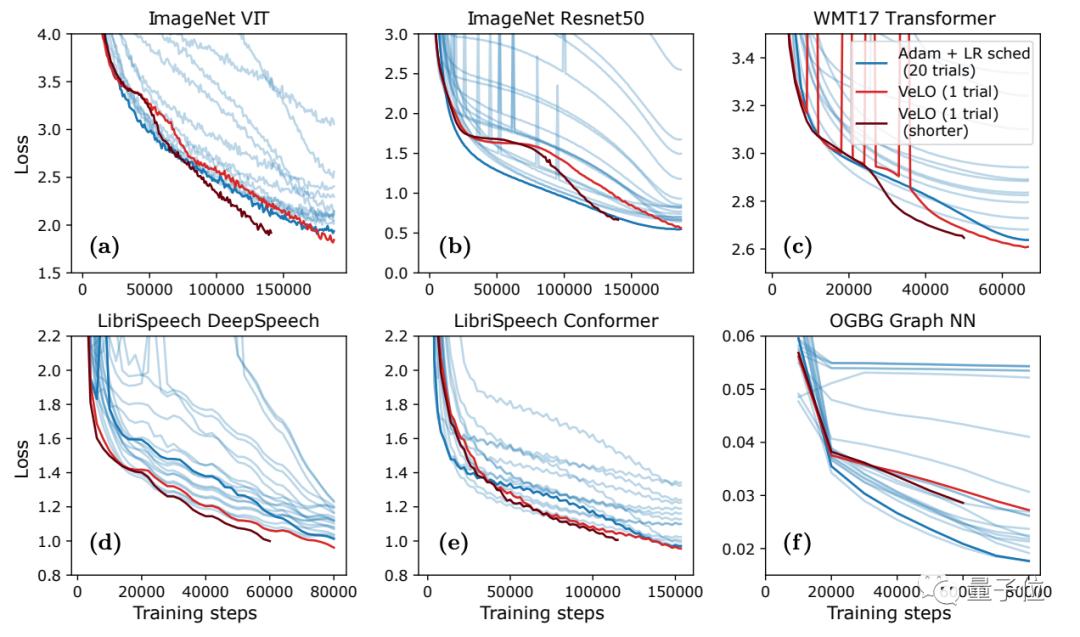
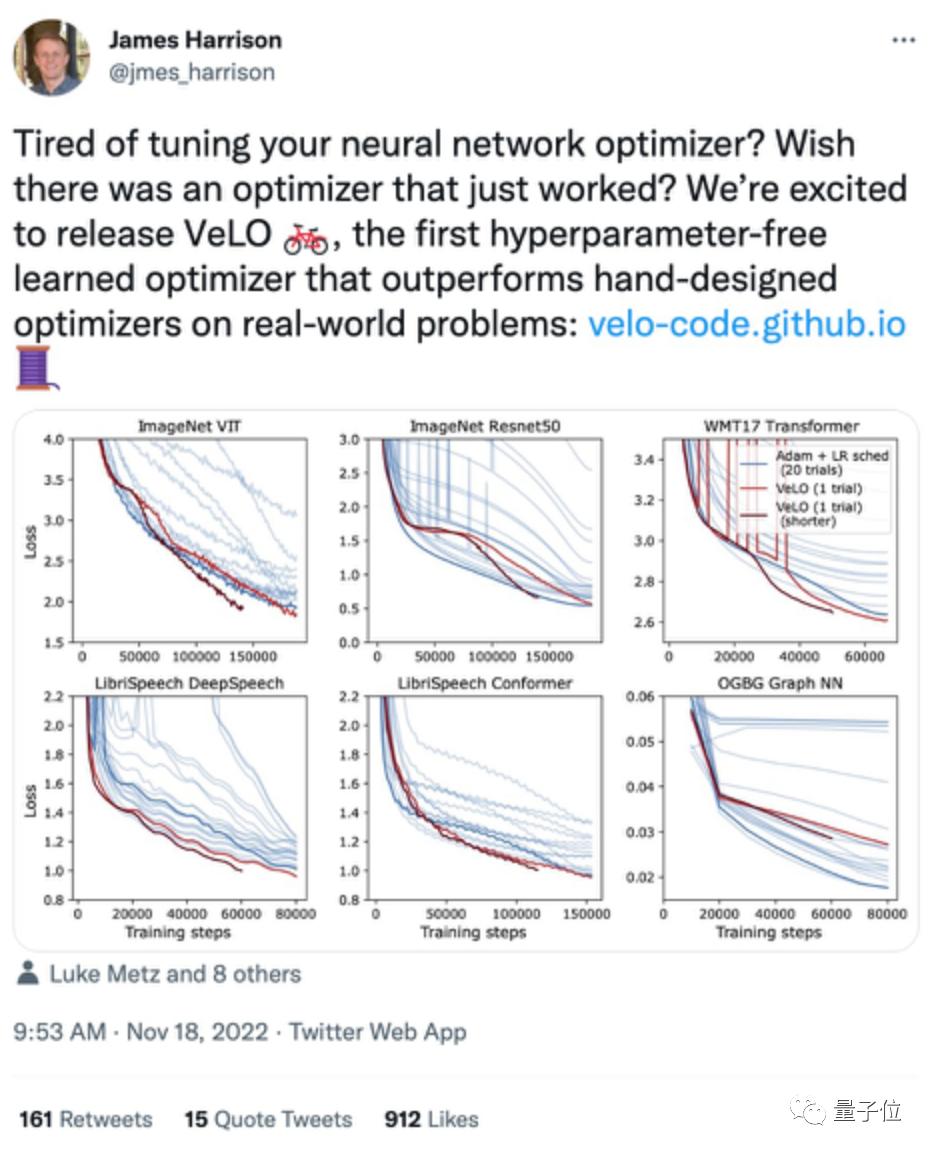
测试得出的结果表明,VeLO 于数量为 83 个的任务之上所产生的加速成效,超出了当下现有的优化器。将其与经典的 Adam 相比较来看,VeLO 在全部的任务当中速度都更为快,其在占比超过 50%的任务里,比经过调整学习率后的 Adam 要快达 4 倍,而在占比 14%的任务中,甚至要快 16 倍。

于6类典型学习任务里头,VeLO在其中5类任务之上的表现皆与Adam相当或者更为出色,论文作者还将VeLO跟其他需要极度调参的优化器去做对比,性能难分高低,这表明开发者终于能够告别反复调试优化器的时日。
开源部署引发行业关注
VeLO现今已然被部署于JAX框架之内,其代码是全然开源的。谷歌大力推广JAX的那种态度是相当明显的,此次径直将最新的优化器放置于JAX之上,开发者能够随时去下载并展开试用。有网友业已开始在项目里尝试这个新工具了。
有声音对训练成本这事提出质疑,4000个TPU月的计算量着实是不小,这计算量跟GPT-3的训练规模差不多,然而鉴于这个优化器能够被数不清的开发者一再使用,所以分摊到每次训练上的成本实际上是很低的,这就好比制作一辆车的成本很高,可每公里的成本就变低了。
论文作者分工透明化
值得一提的是,撰写这篇论文的这些作者们,还将他们各自所做出的具体贡献给公开了。其中对谁写的这篇论文,以及谁搭建的框架,还有谁做的实验,都标注得极为清晰明确。这样一种做法在生物学领域里的论文当中较为常见,然而在人工智能这个圈子里却还算得上是比较新鲜的。
一位来自哈佛的博士生,在前段时间段曾经提出过这个有关建议,其观点认为论文作者应当如同电影演职员表那般进行公开分工。此次谷歌大脑的团队率先展开实践,说不定将会带动整个机器学习圈进而形成一种新的风气。对于读者来说,这样的透明度能够更好地去理解每一篇论文背后的真实工作分配情况。
未来优化器的发展方向
VeLO的现身,意味着优化器设计开启了迈向AI自动生成的全新阶段。在过去的几年当中,尽管有诸多新的优化器问世,然而大部分都未能对Adam的地位产生撼动。此次借助AI构建的优化器,也许能够达成真正的突破。
毋庸置疑,VeLO尚处于初期时段,有待更多实际运用予以检验。然而,它起码证实了一个趋向:相较于人类费尽心思去设计优化器,反倒不如借助AI从海量实践里摸索怎样进行优化。这恰似运用AI去设计芯片,虽说流程繁杂,可是产出成效常常会胜过人工设计。
将这个无需进行参数调整的AI优化器拿来尝试一番,你会这样做吗,欢迎于评论区域把你运用它的体验或者看法予以分享,为了能让更多人瞧见这个全新的工具,点个赞吧。