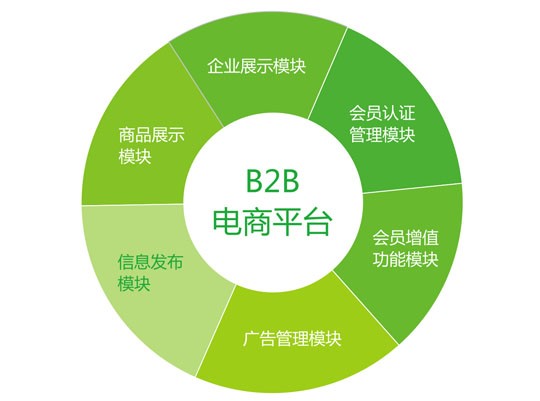
B+树操作弊端

在向普通B+树添加记录时,往往需要进行seek和update的操作,这一过程相当复杂。在磁盘读写过程中,频繁出现大量寻道和磁头移动,极大地降低了效率。每次移动都耗费不少时间,对性能产生了严重影响。这已成为数据库性能优化中亟待解决的问题之一。
B+树结构的特性使得它在更新和插入方面存在限制,尤其在面对高并发和大数据量的应用时,这一不足尤为突出。众多企业的数据库系统因此遭受困扰,迫切需要一种更优的方案来提高处理速度。
LSM的优势
LSM在文件尾端记录数据,有效降低了磁头移动和寻道次数。相较于B+树,这种写入方式在执行速度上更为优越。LevelDB和Cassandra等系统通过分层策略进行数据合并,并非仅依据文件大小进行操作。
LSM是一种既适用于日志也适用于传统单文件索引的解决方案。它能够有效管理更小的独立索引文件,即sstable。通过这种方式,它将B+树的随机IO操作速度提升,已在众多大数据存储系统中得到应用,显著提高了系统的写入效率。
LSM的代价
LSM在写入方面表现出优势,然而也有其代价。读取数据时,需要处理众多索引文件(sstable),这与B+树只需处理一个文件不同。因此,读取过程的复杂度提升,效率相应降低。
此外,合并过程还会耗费部分输入输出资源。在系统实际运作时,这种合并会使用一定量的系统资源,进而对整体性能造成影响。因此,必须对合并活动进行合理的调度和优化,以确保读写性能的平衡。
Lucene的设计

Lucene的Segment设计理念与LSM相似,但存在细微差异。它借鉴了LSM在数据写入方面的优势。写入数据时,Lucene能高效地将数据存入文件,从而提高了写入速度。
Lucene在查询上只能做到接近实时,而非真正的实时。这是因为,在Segment被刷新或提交到磁盘之前,数据暂时存储在内存里,这段时间内无法进行搜索,因此无法实现实时的查询功能。

Lucene索引构建
Lucene进行数据检索时,需要借助事先建立的索引,比如倒排索引中的Term Dictionary。这种索引的构建过程发生在Segment flush阶段,而非实时进行。这样做是为了确保索引的构建达到最高效的状态。

这种设计使得索引结构更为合理,数据排列更有条理,进而提升了查询速度。在具体搜索应用中,采用此法建立的索引能迅速找到所需数据。
FSM与FST及IndexSorting

FSM,也就是有限状态机,它能让系统从初始状态过渡到结束状态,接收到一个字符后可以自行循环或跳转到下一个状态。FST,这是一种特殊的FSM,在Lucene中负责字典查找,而在自然语言处理领域,它还能执行转换任务。

在二进制处理过程中,使用BKD-Tree找到的docID是杂乱的。这时,我们可以选择将其转换成有序的docID数组,或者构建一个BitSet。然后,再将这些结果与其他信息合并。值得注意的是,ES6.0版本之后引入了IndexSorting这一预排序功能。它与查询时的排序不同,实际上它是索引的一个配置项,一旦设置便无法修改。在特定情况下,这种预排序可以提升性能。