在大规模模型训练的潮流中,通信性能宛如默默无闻的舵手,对分布式任务执行速度产生深远影响,对集群GPU的协同效率起到关键作用。同时,系统的运维能力和稳定性,构成了训练过程中的稳固基础,不容忽视。
集合通信核心地位
集群中,集合通信发挥着极其重要的作用。它让不同的 GPU 通过它实现梯度同步和参数更新等操作。这就像团队成员需要实时交流工作信息,只有做到及时沟通,才能有效协作完成任务。通过这种方式,所有 GPU 能够作为一个整体来加速模型训练。因此,集合通信可以说是连接集群中各个 GPU,实现协同工作的关键。
在大型模型训练集群中,若数百乃至上千块GPU不能通过集合通信有效同步数据,训练效果将显著降低。集合通信的性能好坏直接影响到分布式任务的执行速度。
系统运维重要性
训练大型模型不能只关注集群的大小和速度。系统维护和稳定同样重要。若维护不当,会缩短集群的训练时间。比如,某科技公司的一个项目,因为维护问题,原计划一个月完成的训练,拖到了一个半月,增加了不少时间成本。
因此,优秀的系统维护能确保集群持续稳定,使模型训练得以按计划推进,减少不必要的时间和金钱损失。这就像一辆车,只有定期保养,才能保持高速而平稳的行驶。
集合通信库的优化
系统中的关键部分之一是集合通信库,这需要在支持大模型的环境中进行特别优化。BCCL就是一个很好的例子,它是在开源的NCCL基础上,进行了功能的拓展和能力的提升。针对大模型训练的特殊需求,它在可观察性、故障检测和稳定性等方面进行了相应的优化。
优化后,集合通信库的运维性能得到了增强。在处理复杂的大规模模型训练环境中,BCCL展现了出色的适应性,使得集合通信过程更加流畅,确保了模型训练的顺利进行。
集合通信性能观测难题
训练期间,有时会遇到任务运行正常,但整体集群性能却出现下滑的问题。存储系统、RDMA网络、GPU卡等设备都配备了实时监控工具,便于快速发现异常。不过,对于集群通信性能的评估,目前还缺少实时且直观的方法。
当怀疑集合通信存在性能问题时,我们仅有两种检测方法。然而,其中一种检测方法的应用范围较为狭窄,仅能用于检测常规硬件的异常。这就像我们感觉到身体某个部位不适,却难以精确诊断病因一样。
BCCL 实时统计功能
BCCL的实时集合通信带宽统计功能十分突出。这个功能能够在训练时实时监控集合通信的性能,精确地呈现各个阶段的性能状况。这样的功能为故障的排查和训练效果的优化提供了坚实的依据。
即便在通信环境复杂的情况下,BCCL依然依靠其精确的打点技术,确保了带宽统计的准确性。这就像为集合通信配备了一款精确的监控工具,使得训练人员能够随时了解其性能状态。
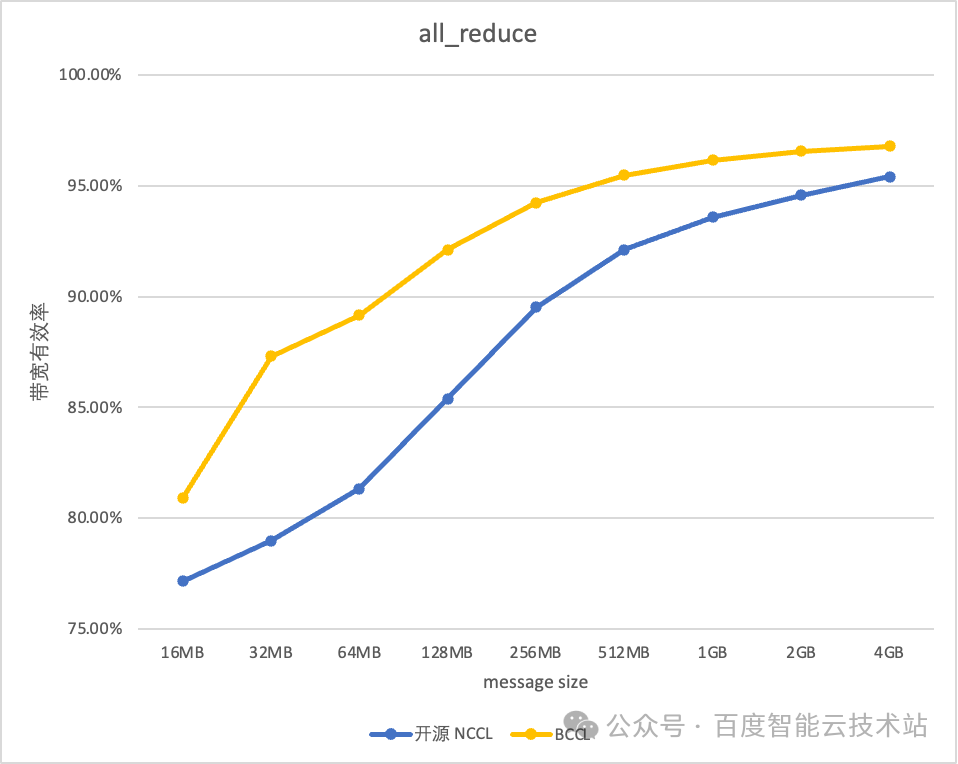
故障定位与性能提升
通信中断时,找到GPU故障点相当困难,程序也难以准确识别是哪块GPU引发了通信异常。此外,网络端口偶尔的上下线问题可能导致训练任务全面终止。尽管如此,对于主流GPU芯片来说,集合通信的性能仍有提升的可能。
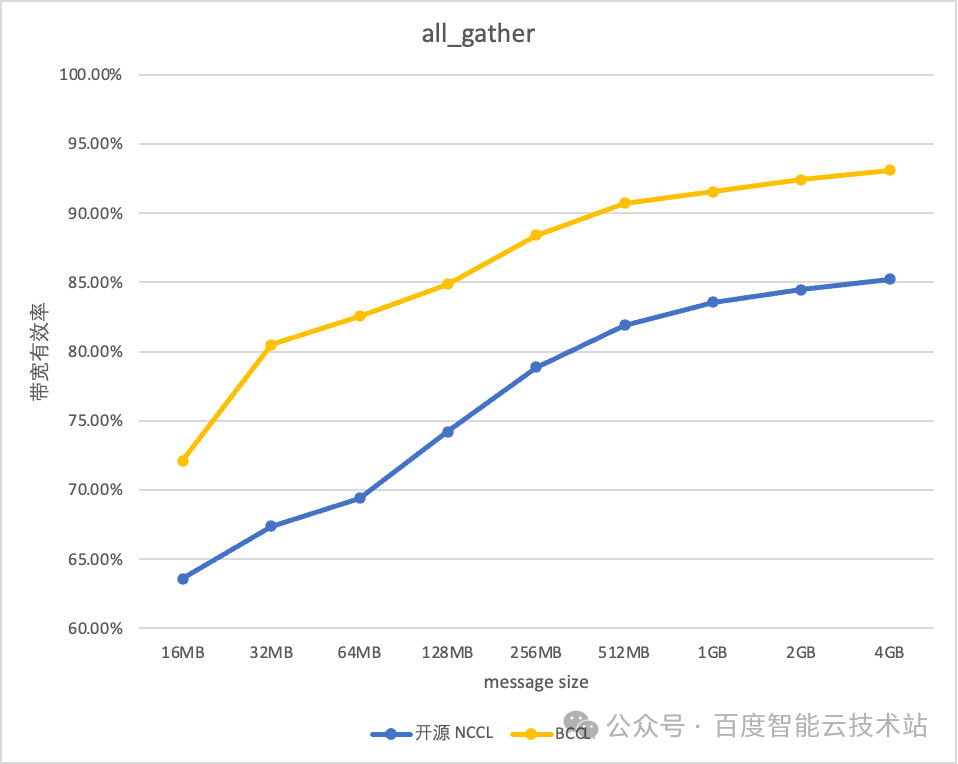
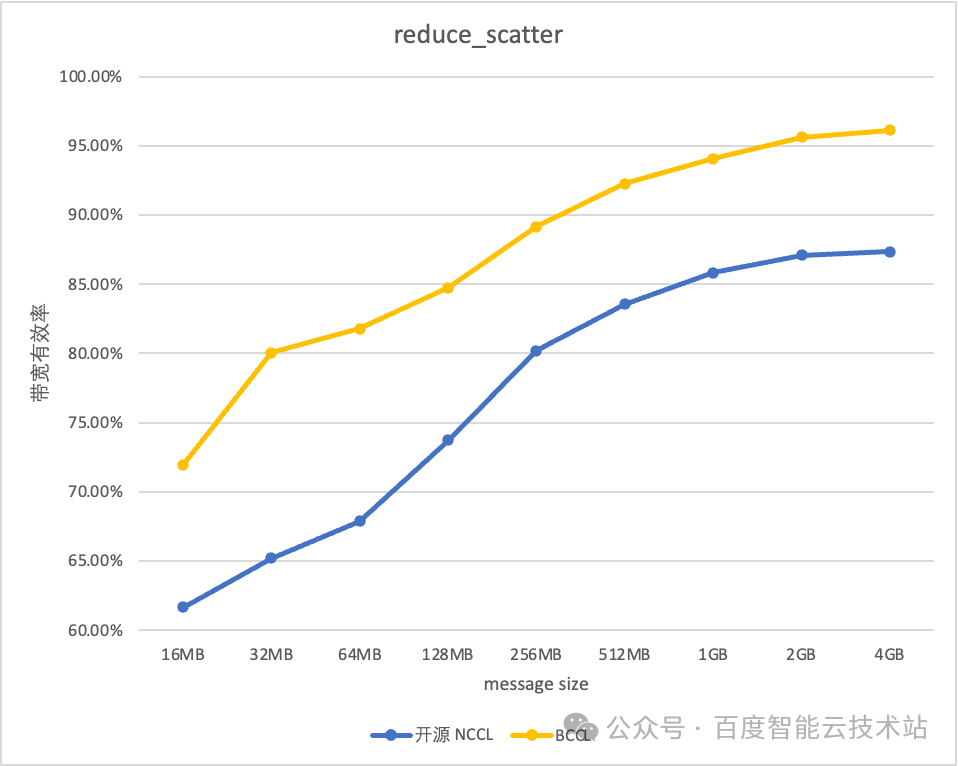
BCCL在运维和稳定性上的改进效果明显。比如百度百舸平台,训练时长利用率高达98%,带宽使用效率达到95%。这样的提升,显著提高了模型训练的效率。
在你的团队里,对于大模型训练,更重视的是通讯效率还是系统维护的能力?不妨给这篇文章点个赞,转发一下,也欢迎留下你的看法。