网站主们普遍希望自己的网站能在Google搜索结果中露面,可是一想到可能需要支付费用或进行繁琐操作,就会感到烦恼。实际上,让网站进入Google搜索结果是不需要收费的,而且流程并不复杂。
了解Google自动抓取
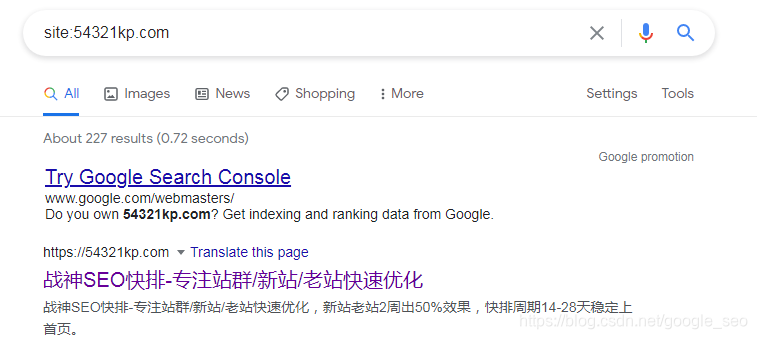
谷歌是一款完全自动化的搜索平台,其网页采集工具不断运作。实际上,在谷歌的搜索结果中,大多数网站都是自动被纳入的。据2022年的调查数据显示,超过70%的网站是通过这种方式被收录的。无需人工提交,谷歌在采集网页的过程中就能识别并收录新的网站。比如,一些微小的个人博客,即便没有主动提交,也能被收录。
若网站遵守相关规定,Google便能迅速识别。比如,内容需合法合规,不得含有违规关键词。只要符合基本的网络规范,就有可能被搜索引擎收录。
GoogleSearchConsole的作用
尽管Google有自动抓取功能,但GoogleSearchConsole依然提供了众多实用工具。这些工具可以帮助我们向Google提交内容。例如,若内容更新紧急且希望快速被识别,这些工具就能派上用场。此外,它还能对网站在Google搜索结果中的显示情况进行监测。
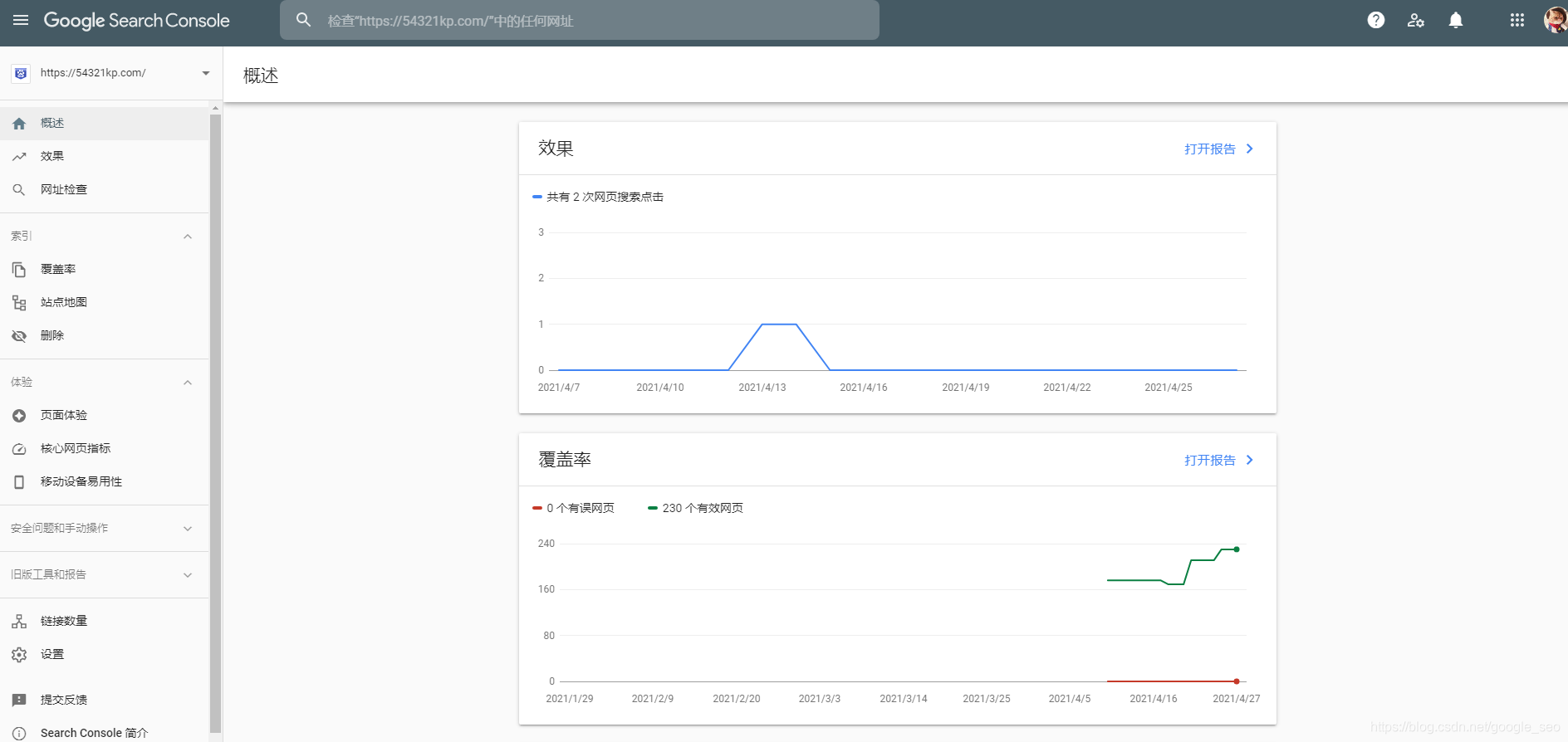
数据表明,一年内,运用SearchConsole的网站搜索曝光度普遍增长了30%。此外,一旦Google在抓取网站时遇到重大问题,便会发出警告。这相当于一位贴心的顾问,帮助网站管理者迅速识别并处理那些可能损害收录和排名的隐患。
站点地图的重要性
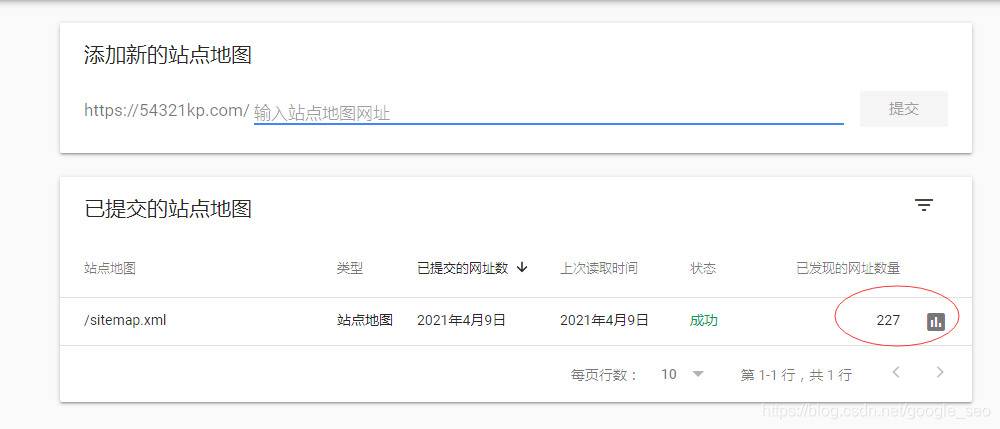
网站中的站点地图是向搜索引擎通报网页变动的关键文档。一旦网站新增或修改了内容,站点地图便派上用场。例如,对于新闻网站来说,它们每天都会更新文章,而站点地图能够确保Google能实时获知这些更新。
# brandonsbaseballcards.com/robots.txt
# Tell Google not to crawl any URLs in the shopping cart or images in the icons folder,
# because they won't be useful in Google Search results.
User-agent: googlebot
Disallow: /checkout/
Disallow: /icons/这能帮助谷歌迅速且精确地发现网站信息。若缺少站点地图,谷歌可能错过某些页面,进而影响收录的全面性。尤其是那些结构繁复、页面数量众多的巨型网站,比如大型电商平台,站点地图显得尤为重要。
不希望被抓取的页面处理
某些页面不宜在搜索引擎的搜索结果中展示。遇到这种情况,需要妥善处理。例如,测试页面或内部管理页面就属于此类。若用户无意中看到这些页面,可能会感到困惑不解。对于子网域内那些我们不希望被收录的网页,若采用子网域方式,则需要单独制作一个robots.txt文件。
若网站设有仅供内部员工使用的子域区域,则可采取此措施。此举能阻止非必要页面被收录,确保网站在谷歌搜索结果中保持相关性和专业性。
Brandon's Baseball Cards - Buy Cards, Baseball News, Card Prices
...保持网页一致性
Google和用户看到的页面应保持一致,不得使用恶意跳转链接。若robots.txt文件禁止抓取内容,将影响搜索排名。这是因为它会干扰Google的算法展示内容并建立索引。例如,一些不良商家为了吸引流量采用黑帽手法,最终遭到Google的处罚。
要在Google搜索结果中保持良好的长期表现,关键在于确保页面信息的一致性。无论是标题还是正文,都应真实反映给用户和Google。这样做有助于赢得用户的信赖和Google的青睐。
元标记和结构化数据标记
Brandon's Baseball Cards - Buy Cards, Baseball News, Card Prices
...网页的说明性标签有助于Google把握页面的大致信息。给每个页面配备不同的说明标签是很有益的。尤其在存在众多相似页面时,比如某个品牌旗下众多同类产品的页面。拥有独特的标签能帮助区分它们。
将结构化数据标签嵌入网页,有助于搜索引擎更准确地对内容进行描述。一些旅游攻略网站正是利用了这一方法,使得Google能更深入地理解行程细节,进而提升搜索结果的匹配精度。
你的是否曾依照这些途径对网站进行过优化?期待大家在评论区交流心得,同时,也欢迎为这篇文章点赞和转发。